ElasticSearch优化-分页查询优化
简介:ElasticSearch优化-分页查询优化,search_after查询,scroll查询遍历
我们使用elasticsearch目的就是为了全文搜索,但是搜索的内容数据可能很多,如果一次性全部返回给前端,会导致IO爆炸,用户搜索时也无法实时显示搜索内容,因此我们需要优化。最为常见的优化就是做分页,类似与MySQL分页的功能。
1. 分页查询
elasticsearch的_search API提供了两个参数【from 和 size】,专门用于分页功能。
- from:表示开始查询的位置,类似与MySQL中的ofset
- size:每一页的文档数量,类似与MySQL中的limit
分页查询具体格式如下:
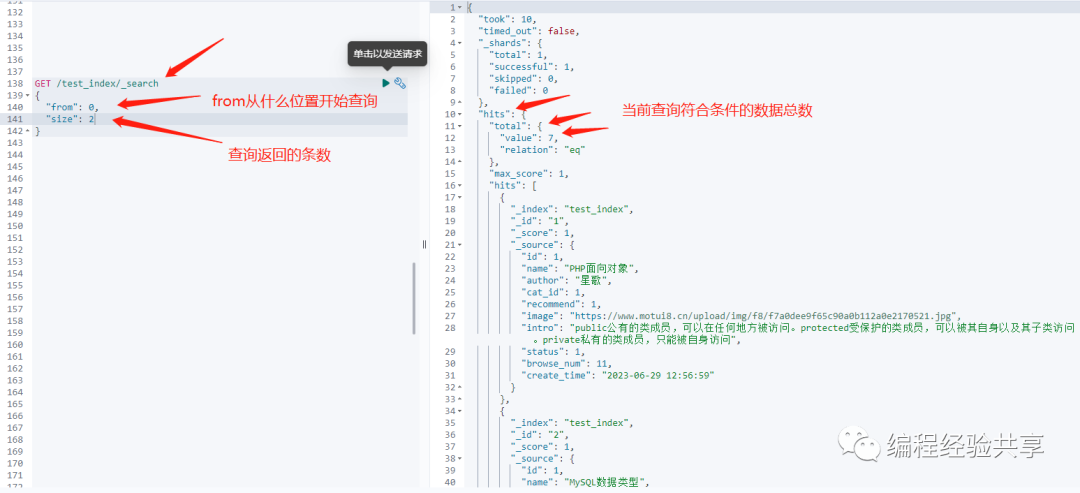
我们在做MySQL分页功能时,通常只需要知道页码值,总条数,每页的数量,ElasticSearch也是一样。
size=每一页的文档数量
from=( 当前页码值 - 1 ) * size
当前分页方法只适合单机或者少量分页功能,但是在分布式及深度分页时,可能导致无法查询,而且会使ES查询变得很慢。
ES在分布式存储时,会将插入的数据分布到不同的服务器节点中,也就是说,上一条数据在服务器节点1(node1)中,下条数据就有可能存储在服务器节点2(node2)中。
当我们使用ES搜索API时,ES会从所有节点中取出 size 条文档数据,最后在连接的结点服务器汇总排序返回给客户端。但是在各个节点获取符合条件的文档数据时,需要先查询 from+size 条数据,再跳过 from 条数据,最后再返回 size 条数据。这个原理和MySQL的分页原理一样,都需要先查询所有符合条件的数据,之后再跳过前面 N 页的数据
举个例子:我们通过node1查询第一页的数据时,ES会先从node1,node2中分别查询符合条件的 from+size 条数据并返回 size 条数据,再由 node1 汇总整合所有节点的数据最后再返回 size 条数据
试想一下,如果我们有10个节点的服务器,每页返回20条数据,查询第100页时,每一个节点都需要查询 (100-1)*20+20=2000 条数据并返回最后的 20 条数据,注意查询的 2000 条数据都会读取到内存中,也很会暂用CPU,这对于服务器来说是一种非常大的消耗。
故此,对于深度分页查询,ES不建议大家使用分页功能。但是elasticsearch提供了 search_after 和 Scroll 遍历查询
2. search_after查询
search_after 查询本质:使用前一页中的一组排序值来检索匹配的下一页。使用 search_after 要求后续的多个请求返回与第一次查询相同的排序结果序列。也就是说,即便在后续翻页的过程中,可能会有新数据写入等操作,但这些操作不会对原有结果集构成影响。
2.1 创建 PIT 视图,这是前置条件不能省
curl -XPOST 'http://localhost:9200/索引名称/_pit?keep_alive=5m'keep_alive=5m,类似scroll的参数,代表视图保留时间是 5 分钟
2.2 创建基础查询语句,这里要设置翻页的条件
curl -XGET 'http://localhost:9200/_search'
{
"size":10,
"query": {
"match" : {
"name" : "elastic"
}
},
"pit": {
"id": "第一步创建PIT返回的pid值",
"keep_alive": "1m"
},
"sort": [
{"response.keyword": "asc"}
]
}2.3 实现后续翻页
curl -XGET 'http://localhost:9200/_search'
{
"size": 10,
"query": {
"match" : {
"host" : "elastic"
}
},
"pit": {
"id": "上一步返回的id值",
"keep_alive": "1m"
},
"sort": [
{"response.keyword": "asc"}
],
"search_after": [
"200",
4
]
}search_after 前一页的最后一个文档的 sort 字段值
3. Scroll 遍历查询
相比于 From + size 和 search_after 返回一页数据,Scroll API 可用于从单个搜索请求中检索大量结果,其方式与传统数据库中游标(cursor)类似。但是实际上,scroll 可以理解为指定一个快照,形成快照之前的数据我们都可以查询,但是形成快照后新增,修改或删除的数据对快照里的数据没有任何影响,还是快照时的原数据。
如果把 From + size 和 search_after 两种请求看做近实时的请求处理方式,那么 scroll 滚动遍历查询显然是非实时的。数据量大的时候,响应时间可能会比较长。
3.1 指定检索语句同时设置 scroll 上下文保留时间
在查询的时候指定【scroll】字段的值,表示上下文保留的时间
curl -XPUT 'http://localhost:9200/索引名称/_search?scroll=3m'
{
"size": 100,
"query": {
"match": {
"name": "elastic"
}
}
}注意:m为分钟的意思
3.2 向后翻页继续获取数据,直到没有要返回的结果为止
curl -XPUT 'http://localhost:9200/_search/scroll'
{
"scroll_id":"上一次请求返回的scroll_id"
}官方文档强调:不再建议使用scroll API进行深度分页。如果要分页检索超过 Top 10,000+ 结果时,推荐使用:PIT + search_after。
有遗漏或者不对的可以在我的公众号留言哦

