ElasticSearch优化-store、_source及高亮问题
简介:ElasticSearch存储优化减少一半存储空间,提升搜索速度
ES是基于lucene以倒排索引为基础实现的存储体系,不遵循关系型数据中范式约定。不过ES数据库中也有自己的优化相关规范,下面我们准备了一些日常工作中经常用到的优化知识点:
| 关键字段 | 值 | 描述 |
| enabled | true | false | 仅存储,不做搜索和聚合分析 |
| index | true | false | 是否构建倒排索引 |
| index_options | docs | freqs | positions | ofsets | 存储倒排索引的哪些信息 |
| norms | true | false | 是否存储归一化相关参数,如果字段仅用于过滤和聚合分析,可以关闭 |
| doc_values | true | false | 如果字段只用于搜索过滤,可以关闭doc_values |
| store | true | false | 是否存储该字段原始值 |
| coerce | true | false | 是否开启自动数据类型转换,比如字符串转数字,浮点转整型等 |
上述表格中,列出了所有用于优化的关键配置项及其作用。其中【store】比较难理解,下面我们就针对【store】深入的探讨一下。
要理解【store】之前,我们先来了解一下【_source】,通过搜索或者获取文档的API获取文档数据时,返回的结果集中会有一个【_source】字段,这里面存储了我们插入的数据,如下图所示:
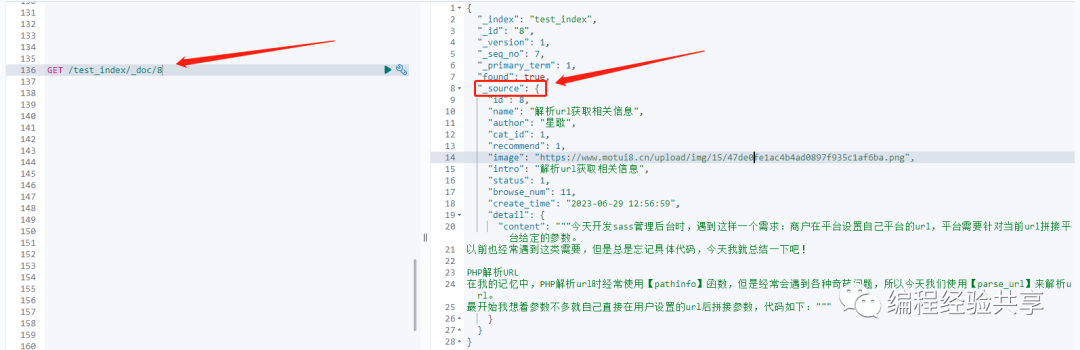
1. store属性与_source的关系
当你将一个 field 的 store 属性设置为 true,这个会在lucene层面处理。lucene是倒排索引,可以执行快速的全文检索,返回符合检索条件的文档id列表。在全文索引之外,lucene也提供了存储字段的值的特性,以支持提供id的查询(根据id得到原始信息)。通常我们在lucene层面存储的field的值是跟随search请求一起返回的(id+field的值)。es并不需要存储你想返回的每一个field的值,因为默认情况下每 一个文档的的完整信息都已经存储在_source中了,因此可以跟随查询结构返回你想要的所有field值。
注意: 从每一个stored field中获取值都需要一次磁盘io,如果想获取多个field的值,就需要多次磁盘io,但是,如果从_source中获取多个field的值,则只需要一次磁盘io,因为_source只是一个字段而已。所以在大多数情况下,从_source中获取是快速而高效的
_source 是把所有字段保存在一个文档的字段中,查询时读取只需要一次 IO。但是包含内容特别多的字段会很占IO,影响性能,通常我们也不需要完整的内容返回(可能只关心摘要),这时候就没必要放到 _source 里一起返回了(当然也可以在查询时指定返回字段)
store:是否在 _source 之外在独立存储一份,这里要说一下 _source 这是源文档,当你存储文档的时候, elasticsearch 会保存一份源文档到 _source 字段中,如果文档的某一字段设置了 store 为 yes (默认为 no),这时候会在 _source 存储之外再为这个字段独立进行存储。
对内容太长的字段,将 store 设置为 yes ,一般来说还应该在 _source 排除 exclude 掉这个字段,这时候索引的字段,不会保存在 _source 里了,会独立存储一份,查询时 _source 里也没有这个字段了,但是还是可以通过指定返回字段来获取,但是会有额外的 IO 开销,因为 _source 的读取只有一次 IO ,而已经 exclude 并设置 store 的字段,是独立存储的需要一个新的 IO
2. 自定义索引Mapping时设置存储原始数据
有些情况下我们希望_source 中不存储原数据,所有字段内容都单独存储,以节省存储空间,我们可以在定义mapping时禁止_source存储内容,所有字段开启存储,格式如下所示:
# 自定义某个索引的Mapping
curl -XPUT 'http://localhost:9200/索引名称'
{
"mappings":{
"_source":{
"enabled":false
},
"properties":{
"title":{
"type":"text",
"store":true
},
"intro":{
"type":"text",
"store":true
},
"author":{
"type":"keyword",
"store":true
},
"cate_id":{
"type":"long",
"doc_values":false,
"norms":false,
"store":true
},
"content":{
"type":"text",
"store":true
},
"create_time":{
"type":"date",
"store":true
},
}
}
}如果一条文档数据节省十几KB,那么数以亿计的是文档数据就可以节省很多的存储空间了
当然,我们也可以通过【includes】设置允许存储的字段,也可以通过【excludes】排除不需要存储的字段,具体格式如下:
# 自定义某个索引的Mapping
curl -XPUT 'http://localhost:9200/索引名称'
{
"mappings":{
"_source":{
"includes":["title","intro"],
"excludes":["content"],
},
"properties":{
"title":{
"type":"text"
},
"intro":{
"type":"text"
},
"content":{
"type":"text",
"store":true
}
}
}
}3. 设置原始数据返回的字段及搜索高亮
一些搜索功能需要我们将搜索匹配的内容进行高亮处理,比如博客网站。对于这个问题ES提供了一个【highlight】字段,你可以对需要高亮的字段内容进行设置,具体格式如下:
# 搜索内容
curl -XGET 'http://localhost:9200/索引名称/_search'
{
"stored_fields":["title","author","cate_id","intro"],
"query":{
"match":{
"content":"测试搜索关键字"
}
},
"highlight":{
"fields":{
"intro":{}
}
}
}设置了字段高亮后,搜索结果中会额外返回一个高亮的字段【highlight】数据,highlight是一个json格式,里面的key是我们设置的高亮字段名,value是高亮后的结果。如果我们需要显示高亮字段,可以将高亮字段替换原字段的内容
高亮字段中匹配的内容被【em】标签包裹,如果需要改变颜色,我们可以通过style设置em标签的样式信息。
默认 em 标签会倾斜,可以通过【font-style:normal】去除
有遗漏或者不对的可以在我的公众号留言哦

